In questo articolo, primo di una lunga serie, proverò a spiegare a chi per i motivi più disparati ne ha bisogno, qualcosa sugli algoritmi.
Infatti ho iniziato a studiare questa interessante e soprattutto utile materia attraverso un libro dell’ottimo Thomas H. Cormen, ovvero Algorithms Unlocked.
Credo che questo lavoro possa diventare utile sia per me che sono in fase di apprendimento, sia per chi leggerà, anche perché le risorse in italiano a riguardo sono abbastanza pochine (togliendo ovviamente le dispense universitarie).
Direi quindi di non perdere altro tempo e buttarci nel discorso ponendoci una importante domanda.
Cos’è un algoritmo?
Beh, dal punto di vista formale questa è una definizione ancora oggetto di discussione, quindi occorre accontentarci, specie inizialmente, di una definizione informale che però racchiude il concetto di algoritmo:
Un algoritmo è un insieme di passi necessari per portare a termine un compito.
Considerando il mondo reale, possiamo dire che eseguiamo algoritmi praticamente in ogni momento.
Vogliamo preparare un bel piatto di pasta? Bene! Non so cucinare, potrei sbagliare qualcosa.
- Scegliere il tipo di pasta che si vuole;
- Prendere una pentola;
- Riempire la pentola con acqua salata;
- Scaldare la pentola finché l’acqua non inizia a bollire;
- Buttare la pasta scelta nella pentola;
- Attendere per il numero di minuti indicato nella scatola;
- Scolare la pasta;
- Condire se volete;
- Servire.
Come potrete ben vedere in cucina sono un disastro, ma ciò non toglie che abbiamo appena visto un esempio di algoritmo che chiunque conosce (magari con qualche variazione).
Spostandoci sui nostri amati computer, invece, possiamo citare due esempi di gruppi di algoritmi che sono abbastanza diffusi:
- Algoritmi del percorso minimo (o pathfinding);
- Algoritmi di criptazione.
Tra gli algoritmi eseguiti da noi umani e quelli eseguiti dai computer è presente un’enorme differenza che occorre tenere ben presente: noi umani possiamo tollerare qualche imprecisione nell’algoritmo (nell’esempio non è stato precisato quale tipo di pasta scegliere, ma non sarà certo un problema!), il computer no.
Un computer non tollera imprecisioni di alcun tipo su un algoritmo, tutto dev’essere già stabilito per non avere spiacevoli sorprese.
Per sapere come scrivere un algoritmo per computer, però, dobbiamo dare una risposta alla seguente domanda: cosa vogliamo da un algoritmo per computer?
Vogliamo semplicemente che, dato un input, l’algoritmo produca sempre la soluzione corretta per un problema attraverso l’utilizzo efficiente delle risorse computazionali.
La correttezza e l’utilizzo di risorse sono due concetti chiave che meritano particolare attenzione.
Correttezza
Cosa significa produrre la soluzione corretta?
Aiutiamoci con un esempio. Mettiamo il caso in cui il nostro navigatore GPS debba calcolare il percorso più veloce per farci spostare da un punto A verso un punto B.
Potrebbe suggerirci un percorso che sì, è il più corto, ma magari è anche il più trafficato o il più lento a causa dei limiti di velocità.
Possiamo dire, in tal caso, che la soluzione data è quella corretta?
Beh, l’algoritmo ha funzionato correttamente, questo è fuor di dubbio, il problema è la mancanza di informazioni (sul traffico e sui limiti di velocità) ricevute in input necessarie a trovare il percorso più veloce.
La soluzione fornita dal navigatore, tenendo conto dell’input che ha ricevuto, può essere quindi considerata corretta.
In alcuni casi, però, si può accettare che un algoritmo possa produrre una risposta non corretta, almeno finché possiamo sapere quanto spesso ciò possa accadere. È questo il caso dell’algoritmo di crittografia asimmetrica RSA.
Ecco un interessantissimo documento in PDF che parla del crittosistema RSA.
Il problema a cui l’algoritmo deve fornire una soluzione è determinare l’appartenenza di un numero all’insieme dei numeri primi o meno.
La prima cosa che si può fare è scrivere un programma che prova a dividere il numero in questione n per tutti i numeri che vanno da 2 a n-1.
Viene facile pensare che se n è composto da centinaia di cifre, il computer potrebbe impiegare un bel po’ di tempo nel calcolo, occorrono quindi delle ottimizzazioni:
- Eliminare tutti i possibili divisori pari una volta stabilito che 2 non è divisore di n;
- Fermarsi quando si arriva a √(n). Infatti, se non si riesce a dividere n per un numero compreso tra 2 e √(n) significa che n è primo.
Un algoritmo che funziona in questo modo può determinare se n è numero primo o numero composto. C’è un problema, però.
Se l’algoritmo stabilisce che n è composto, allora questo lo è, ma se stabilisce che n è primo c’è una piccolissima possibilità che questo sia invece composto, stimabile intorno a 1 volta su 250.
In questo caso siamo quindi davanti ad un algoritmo di approssimazione.
Gli algoritmi di approssimazione vengono incontro a problemi di ottimizzazione che vanno affrontati quando si vuole risolvere un problema che richiederebbe svariato tempo di calcolo in un tempo che sia invece ragionevole.
Manca quindi un algoritmo capace di trovare una soluzione ottima in tempi ragionevoli, e di conseguenza ci si accontenta di una soluzione quasi ottima.
Insomma, possiamo accontentarci della soluzione data.
Utilizzo di risorse
Cosa significa per un algoritmo utilizzare efficientemente le risorse computazionali?
Abbiamo già velatamente parlato di un’unità di misura che ci consente di determinare l’efficacia di un algoritmo, ovvero il tempo.
Provate a pensare ad un algoritmo che fornisce una soluzione corretta ma in moltissimo tempo: che valore potrà mai avere?
Basta pensare all’esempio riguardante il navigatore GPS. Se quest’ultimo impiega svariate ore per calcolare un percorso, tanto vale non usarlo.
Il tempo, però, non è l’unica misura per l’efficacia di un algoritmo. Infatti ci sono anche altri fattori da considerare, vedi la memoria (un algoritmo in esecuzione deve stare entro i limiti di memoria disponibili), la comunicazione con la rete, le operazioni su disco, etc.
In più è da notare che la correttezza di un algoritmo non dipende dal computer utilizzato, mentre il tempo sì.
Tutti i computer possono essere diversi, idem gli input… come trovare un metodo per valutare la velocità di un algoritmo?
Si combinano due idee:
- determiniamo quanto l’algoritmo impiega in funzione della dimensione del suo input (es. dimensione di una lista di oggetti o il numero di incroci facenti parte di una mappa);
- ci concentriamo su quanto velocemente la funzione che rappresenta il tempo di esecuzione dell’algoritmo cresce in base alla dimensione dell’input, ovvero la complessità temporale.
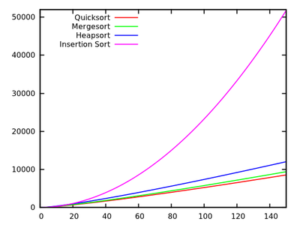
Mettiamo che possiamo determinare che una specifica implementazione di un algoritmo di ricerca in una lista di n elementi impieghi 50n + 125 cicli macchina.
50n supera di molto 125 quando n diventa abbastanza grande, a partire da n>=3.
Man mano che n cresce, quindi, 125 diventa sempre più insignificante, idem il coefficiente di n.
Un altro esempio può essere quello in cui determiniamo la durata di esecuzione di un algoritmo in
20n3 + 100n2 + 300n + 200 cicli macchina.Possiamo dedurre che il tempo di esecuzione dell’algoritmo cresce in n3 perché 100n2 + 300n + 200 conterà sempre di meno all’aumentare di n.
Dal punto di vista pratico, i coefficienti che ignoriamo contano ma dipendono da fattori non rilevanti tali che diventa possibile confrontare due algoritmi A e B con stessa complessità temporale (o tasso di crescita) tali che A però va più veloce di B in alcuni computer e B va più veloce di A in altri.
Se sia A che B producono soluzioni corrette con A che però risulta veloce il doppio rispetto a B, allora chiaramente si preferisce A rispetto a B.
Per paragonare due o più algoritmi nell’astratto è necessario concentrarsi sulla complessità temporale, non considerando (come fatto precedentemente) tutti i coefficienti di termine più basso.
L’importanza degli algoritmi
Per avere un’idea dell’importanza dell’efficienza di un algoritmo basti pensare che dati due algoritmi di ordinamento A e B con A molto più efficiente rispetto a B, non è difficile che l’algoritmo A eseguito su un PC vecchissimo superi nettamente in velocità l’algoritmo B eseguito su un PC di ultima generazione.
Anzi, dirò di più, gran parte delle prestazioni di un sistema dipendono dagli algoritmi utilizzati e non dal computer su cui gira!
Concludendo, possiamo dire che gli algoritmi sono uno strumento indispensabile quando si tratta di tirare fuori il meglio da un computer.
Per tutto l’arco di questo corso cercherò di presentarvi al meglio delle mie possibilità tutto ciò che sto attualmente studiando, sperando che il tutto possa rivelarsi utile per il vostro corso di studi, per i vostri studi personali e quant’altro.